基于深度学习的图像着色系统项目介绍
基于深度学习的图像着色系统项目介绍
库的支持
这里我们用到了以下的库

直接用pip命令安装txt文件中的上述库,非常方便
1 | pip install requirements.txt |
torch
1.1 torch.nn简介与功能
nn是Neural Network的简称。
torch.nn模块是PyTorch提供的,帮助程序员方便(1)创建神经网络和(2)训练神经网络而提供的模块。主要功能包括:
- 创建神经网络
- 训练神经网络
2.1 获取神经网络的模型参数
torch.nn.Parameter 获取模型参数
项目中的重要方法总结与归纳:
将数据转换成Tensor,便于模型使用
torch.nn.Module:
它是所有神经网络模块的基类。
torch.nn.Conv2d
该软件包将用于在由多个输入平面组成的输入信号上应用2D卷积。
BatchNorm2d()
归一化
函数参数讲解:
BatchNorm2d()函数数学原理如下:

1 | BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) |
1.num_features:一般输入参数为batch_sizenum_featuresheight*width,即为其中特征的数量,即为输入BN层的通道数;
2.eps:分母中添加的一个值,目的是为了计算的稳定性,默认为:1e-5,避免分母为0;
3.momentum:一个用于运行过程中均值和方差的一个估计参数(我的理解是一个稳定系数,类似于SGD中的momentum的系数);
4.affine:当设为true时,会给定可以学习的系数矩阵gamma和beta
torch.nn.ReLU
它将按元素应用于整流线性单位函数:ReLU(x)= max(0, x)
torch.nn.Upsample
它用于对给定的多通道1D, 2D或3D数据进行升采样。
张量tensor
torch.Tensor()是一个类,是默认张量类型torch.FloatTensor()的别名,用于生成一个单精度浮点类型的张量。
张量连接
torch.cat(inputs, dimension=0) → Tensor:在给定维度上对输入的张量序列seq 进行连接操作,只需满足指定纬度的长度相同
torch.nn.Sequential
它是一个顺序容器,其中模块的添加顺序与在构造函数中传递模块时的顺序相同。
torch.nn.Softmax
它用于将softmax函数应用于n维输入张量以重新缩放它们。之后, n维输出Tensor的元素位于0、1的范围内, 且总和为1。
torch.nn.ConvTranspose2d
该软件包将用于在由多个输入平面组成的输入图像上应用2D转置卷积运算符。
TORCH.NN.FUNCTIONAL.INTERPOLATE
1 | torch.nn.functional.interpolate(input, size=None, scale_factor=None, mode=‘nearest’, align_corners=None, recompute_scale_factor=None, antialias=False) |
将输入input上采样或下采样到指定的size或缩放因子上scale_factor
resize使用的算法由mode参数决定,mode默认为nearest, 可选参数有nearest/linear(3D Inputs-only)/bilinear/bicubic(4D Inputs-only)/trilinear(5D Inputs-only)/area/nearest-exact
支持输入input为3/4/5维数据,输入数据维度的顺序为mini-batch x channels x [optional depth] x [optional height] x width
参数
input:输入向量
size(int or Tuple[int] or Tuple[int, int] or Tuple[int, int, int])输出数据的空间尺度
mode (str) :采样算法
align_corners:输出的结果是否角对齐,对插值后的边的处理方式有所不同,参考一文看懂align_corners
recompute_scale_factor:是否重新计算scale_factor,默认None,选择特定的插值方式时可用
align_corners为False和True时输出的对比:

2.2 主要的容器
| 名称 | Containers | |
|---|---|---|
| 1)torch.nn.Module | 它是所有神经网络模块的基类。 | |
| 2)torch.nn.Sequential | 它是一个顺序容器,其中模块的添加顺序与在构造函数中传递模块时的顺序相同。 | |
| 3)torch.nn.ModuleList | 这会将子模块保存在列表中。 | |
| 4)torch.nn.ModuleDict | 这会将子模块保存在目录中。 | |
| 5)torch.nn.ParameterList | 这会将参数保存在列表中。 | |
| 6)torch.nn.parameterDict | 这会将参数保存在目录中。 |
2.3 线性层
| 线性层 | ||
|---|---|---|
| 1)PyTorch PlaceHolder | 它是一个占位符身份运算符, 对参数不敏感。 | |
| 2)torch.nn.Linear | 它用于对输入数据进行线性变换:y = xAT + b | |
| 3)torch.nn.Bilinear | 它用于对输入数据进行双线性变换:y = x1 Ax2 + b |
2.4 非线性激活函数
| 非线性激活(加权和, 非线性) | ||
|---|---|---|
| 1)torch.nn.ELU | 它将用于应用按元素的函数:ELU(x)= max(0, x)+ min(0, α*(exp(x)-1)) | |
| 2)torch.nn.Hardshrink | 它将用于应用硬收缩函数逐元素函数: | |
| 3)torch.nn.LeakyReLU | 它将用于应用按元素的函数:LeakyReLu(x)= max(0, x)+ negative_slope * min(0, x) | |
| 4)torch.nn.LogSigmoid | 它将用于应用逐元素函数: | |
| 5)torch.nn.MultiheadAttention | 它用于允许模型关注来自不同表示子空间的信息 | |
| 6)torch.nn.PReLU | 它将用于应用按元素的函数:PReLU(x)= max(0, x)+ a * min(0, x) | |
| 7)torch.nn.ReLU | 它将按元素应用于整流线性单位函数:ReLU(x)= max(0, x) | |
| 8)torch.nn.ReLU6 | 它将用于应用按元素的函数:ReLU6(x)= min(max(0, x), 6) | |
| 9)torch.nn.RReLU | 如本文所述, 它将用于逐元素地应用随机泄漏整流线性单位函数: | |
| 10)torch.nn.SELU | 它将按以下方式应用按元素的函数:SELU(x)= scale *(max(0, x)+ min(0, a *(exp(x)-1)))这里α= 1.6732632423543772772848170429916717和scale = 1.0507009873554804934193193349852946。 | |
| 11)PyTorch | 它将按以下方式应用按元素的功能: | |
| 12)PyTorch | 它将按以下方式应用按元素的功能: | |
| 13)torch.nn.Softplus | 它将按以下方式应用按元素的功能: | |
| 14)torch.nn.Softshrink | 它将按元素应用软收缩功能, 如下所示: | |
| 15)torch.nn.Softsign | 它将按以下方式应用按元素的功能: | |
| 16)torch.nn.Tanh | 它将按以下方式应用按元素的功能: | |
| 17)torch.nn.Tanhshrink | 它将按以下方式应用按元素的函数:Tanhshrink(x)= x-Tanh(x) | |
| 18)torch.nn.Threshold | 它将用于阈值输入张量的每个元素。阈值定义为: |
2.5 非线性激活函数
| 非线性激活(其他) | ||
|---|---|---|
| 1)torch.nn.Softmin | 它用于将softmin函数应用于n维输入张量以重新缩放它们。之后, n维输出Tensor的元素位于0、1的范围内, 且总和为1。Softmin定义为: | |
| 2)torch.nn.Softmax | **它用于将softmax函数应用于n维输入张量以重新缩放它们。之后, n维输出Tensor的元素位于0、1的范围内, 且总和为1。**Softmax定义为: | |
| 3)torch.nn.Softmax2d | 它用于将SoftMax应用于要素上的每个空间位置。 | |
| 4)torch.nn.LogSoftmax | 它用于将LogSoftmax函数应用于n维输入张量。 LofSoftmax函数可以定义为: | |
| 5)torch.nn.AdaptiveLogSoftmaxWithLoss | 这是训练具有较大输出空间的模型的策略。标签分布高度不平衡时非常有效 |
2.6 归一化处理
| 归一化层 | ||
|---|---|---|
| 1)torch.nn.BatchNorm1d | 它用于对2D或3D输入应用批量归一化。 | |
| 2)torch.nn.BatchNorm2d | 它用于在4D上应用批量归一化。 | |
| 3)torch.nn.BatchNorm3d | 它用于对5D输入应用批量归一化。 | |
| 4)torch.nn.GroupNorm | 它用于在最小输入批次上应用组归一化。 | |
| 5)torch.nn.SyncBatchNorm | 它用于对n维输入应用批量归一化。 | |
| 6)torch.nn.InstanceNorm1d | 它用于在3D输入上应用实例规范化。 | |
| 7)torch.nn.InstanceNorm2d | 它用于在4D输入上应用实例规范化。 | |
| 8)torch.nn.InstanceNorm3d | 它用于在5D输入上应用实例规范化。 | |
| 9)torch.nn.LayerNorm | 它用于在最小输入批次上应用层归一化。 | |
| 10)torch.nn.LocalResponseNorm | 它用于对由多个输入平面组成的输入信号进行局部响应归一化, 其中通道占据第二维。 |
2.7 各种损失函数
| Loss function | ||
|---|---|---|
| 1)torch.nn.L1Loss | 它用于衡量输入x和目标y中每个元素之间的平均绝对误差的标准。未减少的损失可描述为:l(x, y)= L = {l1, …, ln}, ln = | xn-yn |, 其中N是批次大小。 | |
| 2)torch.nn.MSELoss | 它用于衡量输入x和目标y中每个元素之间的均方误差的标准。未减少的损失可描述为:l(x, y)= L = {l1, …, ln}, ln =(xn-yn)2, 其中N是批次大小。 | |
| 3)torch.nn.CrossEntropyLoss | 此条件将nn.LogSoftmax()和nn.NLLLoss()组合在一个类中。当我们训练C类的分类问题时, 这将很有帮助。 | |
| 4)torch.nn.CTCLoss | 连接主义者的时间分类损失计算连续时间序列和目标序列之间的损失。 | |
| 5)torch.nn.NLLLoss | 负对数似然损失用于训练C类的分类问题。 | |
| 6)torch.nn.PoissonNLLLoss | 目标的Poisson分布为负的对数似然损失-目标(Posson(input)loss(input, target)= input-target * log(target!)) | |
| 7)torch.nn.KLDivLoss | 这对于连续分布是有用的距离度量, 并且在我们对连续输出分布的空间进行直接回归时也很有用。 | |
| 8)torch.nn.BCELoss | 它用于创建衡量目标和输出之间的二进制交叉熵的标准。未减少的损失可描述为:l(x, y)= L = {l1, …, ln}, ln = -wn [yn * logxn +(1-yn)* log(1-xn)], 其中N是批次大小。 | |
| 9)torch.nn.BCEWithLogitsLoss | 它在一个类别中将Sigmoid层和BCELoss结合在一起。通过将操作合并到一层, 我们可以利用log-sum-exp技巧来实现数值稳定性。 | |
| 10)torch.nn.MarginRankingLoss | 它创建一个标准来测量给定输入x1, x2, 两个1D迷你批量张量和包含1或-1的标签1D迷你批量张量y的损耗。迷你批次中每个样本的损失函数如下:loss(x, y)= max(0, -y *(x1-x2)+ margin | |
| 11)torch.nn.HingeEmbeddingLoss | HingeEmbeddingLoss度量给定输入张量x和包含1或-1的标签张量y的损失。它用于测量两个输入是否相似或不相似。损失函数定义为: | |
| 12)torch.nn.MultiLabelMarginLoss | 它用于创建优化输入x和输出y之间的多类多分类铰链损耗的标准。 | |
| 13)torch.nn.SmoothL1Loss | 它用于创建一个标准, 如果绝对逐项误差低于1, 则使用平方项, 否则使用L1项。也称为胡贝尔损耗: | |
| 14)torch.nn.SoftMarginLoss | 它用于创建优化输入张量x和目标张量y之间(包含1或-1)的两类分类逻辑损失的标准。 | |
| 15)torch.nn.MultiLabelSoftMarginLoss | 它用于创建一个标准, 该标准基于输入x与大小(N, C)的目标y之间的最大熵来优化多标签对所有损失。 | |
| 16)torch.nn.CosineEmbeddingLoss | 它用于创建一个标准, 该标准测量给定输入张量x1, x2和张量标签y的值为1或-1的损失。它用于使用余弦距离来测量两个输入是相似还是相异。 | |
| 17)torch.nn.MultiMarginLoss | 它用于创建优化输入x和输出y之间的多类分类铰链损耗的标准。 | |
| 18)torch.nn.TripletMarginLoss | 它用于创建衡量给定输入张量x1, x2, x3和值大于0的余量的三重态损失的标准。它用于衡量样本之间的相对相似性。三元组由锚点, 正例和负例组成。 L(a, p, n)= max {d(ai, pi)-d(ai, ni)+ margin, 0} |
2.8 CNN卷积层
| Convolution layers | ||
|---|---|---|
| 1)torch.nn.Conv1d | 该软件包将用于对由多个输入平面组成的输入信号进行一维卷积。 | |
| 2)torch.nn.Conv2d | 该软件包将用于在由多个输入平面组成的输入信号上应用2D卷积。 | |
| 3)torch.nn.Conv3d | 该软件包将用于在由多个输入平面组成的输入信号上应用3D卷积。 | |
| 4)torch.nn.ConvTranspose1d | 该软件包将用于在由多个输入平面组成的输入图像上应用一维转置卷积算符。 | |
| 5)torch.nn.ConvTranspose2d | 该软件包将用于在由多个输入平面组成的输入图像上应用2D转置卷积运算符。 | |
| 6)torch.nn.ConvTranspose3d | 该软件包将用于在由多个输入平面组成的输入图像上应用3D转置卷积运算符。 | |
| 7)torch.nn。展开 | 它用于从成批的输入张量中提取滑动局部块。 | |
| 8)PyTorch折叠 | 它用于将一系列滑动局部块组合成一个大的包含张量。 |
2.9 pooling层
| Pooling layers | ||
|---|---|---|
| 1)torch.nn.MaxPool1d | 它用于在由多个输入平面组成的输入信号上应用一维最大池。 | |
| 2)torch.nn.MaxPool2d | 它用于在由多个输入平面组成的输入信号上应用2D max池。 | |
| 3)torch.nn.MaxPool3d | 它用于在由多个输入平面组成的输入信号上应用3D max池。 | |
| 4)torch.nn.MaxUnpool1d | 它用于计算MaxPool1d的局部逆。 | |
| 5)torch.nn.MaxUnpool2d | 它用于计算MaxPool2d的局部逆。 | |
| 6)torch.nn.MaxUnpool3d | 它用于计算MaxPool3d的局部逆。 | |
| 7)torch.nn.AvgPool1d | 它用于在由多个输入平面组成的输入信号上应用一维平均池。 | |
| 8)torch.nn.AvgPool2d | 它用于在由多个输入平面组成的输入信号上应用2D平均池。 | |
| 9)torch.nn.AvgPool3d | 它用于在由多个输入平面组成的输入信号上应用3D平均池。 | |
| 10)torch.nn.FractionalMaxPool2d | 它用于在由多个输入平面组成的输入信号上应用2D分数最大池化。 | |
| 11)torch.nn.LPPool1d | 它用于在由多个输入平面组成的输入信号上应用一维功率平均池。 | |
| 12)torch.nn.LPPool2d | 它用于在由多个输入平面组成的输入信号上应用2D功率平均池。 | |
| 13)torch.nn.AdavtiveMaxPool1d | 它用于在由多个输入平面组成的输入信号上应用一维自适应最大池化。 | |
| 14)torch.nn.AdavtiveMaxPool2d | 它用于在由多个输入平面组成的输入信号上应用2D自适应最大池化。 | |
| 15)torch.nn.AdavtiveMaxPool3d | 它用于在由多个输入平面组成的输入信号上应用3D自适应最大池化。 | |
| 16)torch.nn.AdavtiveAvgPool1d | 它用于在由多个输入平面组成的输入信号上应用一维自适应平均池。 | |
| 17)torch.nn.AdavtiveAvgPool2d | 它用于在由多个输入平面组成的输入信号上应用2D自适应平均池。 | |
| 18)torch.nn.AdavtiveAvgPool3d | 它用于在由多个输入平面组成的输入信号上应用3D自适应平均池。 |
2.10 填充层
| 填充层 | ||
|---|---|---|
| 1)torch.nn.ReflectionPad1d | 它将使用输入边界的反射填充输入张量。 | |
| 2)torch.nn.ReflactionPad2d | 它将使用输入边界的反射来填充输入张量。 | |
| 3)torch.nn.ReplicationPad1 | 它将使用输入边界的复制来填充输入张量。 | |
| 4)torch.nn.ReplicationPad2d | 它将使用输入边界的复制来填充输入张量。 | |
| 5)torch.nn.ReplicationPad3d | 它将使用输入边界的复制来填充输入张量。 | |
| 6)torch.nn.ZeroPad2d | 它将用零填充输入张量边界。 | |
| 7)torch.nn.ConstantPad1d | 它将用恒定值填充输入张量边界。 | |
| 8)torch.nn.ConstantPad2d | 它将用恒定值填充输入张量边界。 | |
| 9)torch.nn.ConstantPad3d | 它将用恒定值填充输入张量边界。 |
2.11 RNN网络层
| Recurrent layers | ||
|---|---|---|
| 1)torch.nn.RNN | 它用于将具有tanh或ReLU非线性的多层Elman RNN应用于输入序列。每一层为输入序列中的每个元素计算以下函数:ht = tanh(Wih xt + bih + Whh tt-1 + bhh) | |
| 2)Torch.nn.LSTM | 它用于将多层长期短期记忆(LSTM)RNN应用于输入序列。每一层为输入序列中的每个元素计算以下功能: | |
| 3)GNUPyTorch | 它用于将多层门控循环单元(GRU)RNN应用于输入序列。每一层为输入序列中的每个元素计算以下功能: | |
| 4)torch.nn.RNNCell | 它用于将具有tanh或ReLU非线性的Elman RNN单元应用于输入序列。每一层为输入序列中的每个元素计算以下函数:h’= tanh(Wih x + bih + Whh h + bhh)使用ReLU代替tanh | |
| 5)torch.nn.LSTMCell | 它用于将长短期记忆(LSTM)单元应用于输入序列。每一层为输入序列中的每个元素计算以下函数:其中σ是S型函数, 而*是Hadamard乘积。 | |
| 6)torch.nn.GRUCell | 它用于将门控循环单元(GRU)单元应用于输入序列。每一层为输入序列中的每个元素计算以下功能: |
2.12 Dropout层定义
| Dropout layers | ||
|---|---|---|
| 1)torch.nn.Dropout | 它用于调节和预防神经元的共适应。培训过程中的一个因素会缩放输出。这意味着模块将在评估期间计算身份函数。 | |
| 2)torch.nn.Dropout2d | 如果要素图中的相邻像素相关, 则torch.nn.Dropout不会使激活规则化, 并且会降低有效学习率。在这种情况下, torch.nn.Dropout2d()用于促进要素图之间的独立性。 | |
| 3)torch.nn.Dropout3d | 如果要素图中的相邻像素相关, 则torch.nn.Dropout不会使激活规则化, 并且会降低有效学习率。在这种情况下, torch.nn.Dropout2d()用于促进要素图之间的独立性。 | |
| 4)torch.nn.AlphaDropout | 它用于在输入上应用Alpha Dropout。 Alpha Dropout是一种Dropout, 可以保持自规范化属性。 |
2.13 Sparse layers
| Sparse layers | ||
|---|---|---|
| 1)torch.nn嵌入 | 它用于存储单词嵌入, 并使用索引检索它们。模块的输入是索引列表, 输出是相应的词嵌入。 | |
| 2)torch.nn.EmbeddingBag | 它用于计算嵌入的”袋子”的总和或平均值, 而无需实例化中间嵌入。 |
2.14 距离功能
| 距离功能 | ||
|---|---|---|
| 1)torch.nn.Cosine相似度 | 它将返回x1和x2之间的余弦相似度(沿dim计算)。 | |
| 2)torch.nn.PairwiseDistance | 它使用p范数计算向量v1, v2之间的成批成对距离: |
2.15 可视化层
| Vision layers | ||
|---|---|---|
| 1)torch.nn.PixelShuffle | 用于将形状为(, C×r2, H, W)的张量的元素重新排列为形状为(, C, H×r, W, r)的张量的元素 | |
| 2)torch.nn.Upsample | 它用于对给定的多通道1D, 2D或3D数据进行升采样。 | |
| 3)torch.nn.upsamplingNearest2d | 它用于对由多个输入通道组成的输入信号进行2D最近邻居上采样。 | |
| 4)torch.nn.UpsamplingBilinear2d | 用于将二维双线性上采样应用于由多个输入通道组成的输入信号。 |
2.16 并行数据层
| DataParallel层(多GPU, 分布式) | ||
|---|---|---|
| 1)torch.nn.DataParallel | 它用于在模块级别实现数据并行性。 | |
| 2)torch.nn.DistributedDataParallel | 它用于实现分布式数据并行性, 它基于模块级别的torch.distributed包。 | |
| 3)torch.nn.DistributedDataParallelCPU | 它用于在模块级别为CPU实现分布式数据并行性。 |
2.17 各种工具
| 1)torch.nn.clip_grad_norm_ | 它用于裁剪可迭代参数的梯度范数。 | |
| 2)torch.nn.clip_grad_value_ | 用于将可迭代参数的梯度范数裁剪为指定值。 | |
| 3)torch.nn.parameters_to_vector | 用于将参数转换为一个向量。 | |
| 4)torch.nn.vector_to_parameters | 它用于将一个向量转换为参数。 | |
| 5)torch.nn.weight_norm | 它用于对给定模块中的参数应用权重归一化。 | |
| 6)torch.nn.remove_weight_norm | 它用于删除模块的权重归一化和重新参数化。 | |
| 7)torch.nn.spectral_norm | 它用于将频谱归一化应用于给定模块中的参数。 | |
| 8)torch.nn.PackedSequence | 它将用于保存打包序列的数据和batch_size的列表。 | |
| 9)torch.nn.pack_padded_sequence | 它用于打包包含可变长度填充序列的Tensor。 | |
| 10)torch.nn.pad_packed_sequence | 它用于填充打包的可变长度序列批次。 | |
| 11)torch.nn.pad_sequence | 它用于填充具有填充值的可变长度张量列表。 | |
| 12)torch.nn.pack_sequence | 它用于打包可变长度张量的列表 | |
| 13)torch.nn.remove_spectral_norm | 它用于删除模块的频谱归一化和重新参数化。 |
2.18 tensor简介
在PyTorch中,torch.Tensor是存储和变换数据的主要工具。
Tensor与Numpy的多维数组非常相似。
Tensor还提供了GPU计算和自动求梯度等更多功能,这些使Tensor更适合深度学习。****
2.创建Tensor
2.1 直接创建一个5*3的未初始化的Tensor:
1 | x = torch.empty(5,3) |
2.2 创建一个5*3的随机初始化的Tensor
torch.rand:返回一个张量,包含了从区间[0,1)的均匀分布中抽取一组随机数,形状由可变参数size定义。
原型:
1 | torch.rand(size,out=None,dtype=None,layout=torch.strided,device=None, |
举例:
1 | x = torch.rand(5,3) |
torch.randn:返回一个张量,包含了从标准正态分布(Normal distribution)(均值为0,方差为1,即高斯白噪声)中抽取一组随机数,形状由可变参数sizes定义。
1 | x = torch.randn(2,3) |
2.3 创建全为0的Tensor(指定数据类型)
1 | x = torch.zeros(5,3,dtype=long) |
2.4 根据数据直接创建
1 | x = torch.tensor([5.5,3]) |
2.5 tensor.new_ones:返回一个与size大小相同的用1填充的张量;
默认情况下,返回的Tensor具有与此张量相同的torch.dtype和torch.device;
1 |
|
2.6 torch.rand_like:返回与输入相同大小的张量,该张量由区间[0,1)上均匀的随机数填充。
原型:
1 | torch.rand_like(input,dtype=None,layout=None,device=None,requires_grad=False, |
torch.rand_like(input)相当于torch.rand(input.size(),dtype=input.dtype,layout=input.layout,device=input.device)
举例:
1 | x = torch.rand_like(x,dtype=torch.float) |
2.7 torch.arange:根据(首,尾,步长)生成tensor
2.8 其余tensor的构造函数
1 | Tensor(*sizes) 基础构造函数 |
这些创建方法都可以在创建的时候指定数据类型dtype和存放device(cpu/gpu)
3.Tensor的操作
2.1 Tensor的加法操作:
加法形式一:
1 | x = torch.rand(5, 3) |
加法形式二:
1 | z=torch.add(x,y) |
加法形式三:
1 | y.add_(x) |
2.2 Tensor的索引操作:
我们还可以使用类似Numpy的索引操作来访问Tensor的一部分。需要注意的是:索引出来的结果与原数据共享内存,也即修改一个,另一个也会跟着修改。
1 | y = x[0,:] |
除了常用的索引选择数据之外,PyTorch还提供了一些高级的选择函数:
1 | index_select(input,dim,index) #在指定维度dim上选取过,比如选取某些行,某些列 |
4.Tensor数据类型的转换
使用独立的函数如 int(),float()等进行转换
1 | long_tensor = tensor.long() |
使用torch.type()函数
1 | t2=t1.type(torch.FloatTensor) |
使用type_as()函数
1 | t3=t1.type_as(t2) |
- Tensor的形状修改
5.1 view()
用view()来改变Tensor的形状:
1 | y = x.view(15) |
-1所指的维度可以根据其他的维度推出来
1 | z = x.view(-1,5) |
注意:
view()返回的新tensor与源tensor共享内存,实际上就是同一个tensor,也就是更改一个,另一个也会跟着改变。
(顾名思义,view()仅仅改变了对这个张量的观察角度)
Pytorch中的Tensor支持包含一百多种操作,包含转置,索引,切片,数学运算,线性代数,随机数等。
- Tensor的数据转换
6.1 item()
作用:它可以将一个标量Tensor转换为一个Python number:
1 | x = torch.randn(1) |
6.2 Tensor 转 NumPy
使用numpy()将Tensor转换成NumPy数组:
注意,这样产生的NumPy数组与Tensor共享相同的内存,改变其中一个另一个也会改变!
1 | a = torch.ones(5) |
6.3 NumPy数组转Tensor
使用from_numpy()将NumPy数组转换为Tensor:
注意,这样产生的NumPy数组与Tensor共享相同的内存,改变其中一个另一个也会改变!
1 | a = np.ones(5) |
- Tensor的广播机制
当对两个形状不同的Tensor按元素运算时,可能会触发广播机制(broadcasting)机制:先适当复制元素使这两个Tensor形状相同后再按元素运算。
1 | x = torch.arange(1, 3).view(1,2) #[1,2] |
结果:
1 | tensor([[2, 3], |
8.tensor运算的内存开销
索引,view()是不会开辟新的内存的,而像y=x+y这样的运算是会开辟新的内存的,然后y指向新的内存。
- Tensor ON GPU
用方法to()可以将Tensor在CPU和GPU之间相互移动。
以下代码只有在PyTorch GPU版本上才会执⾏
1 | if torch.cuda.is_available(): |
Ski-image
skimage的简介
skimage即是Scikit-Image。基于python脚本语言开发的数字图片处理包,比如PIL,Pillow, opencv, scikit-image等。
PIL和Pillow只提供最基础的数字图像处理,功能有限。
opencv实际上是一个c++库,只是提供了python接口,更新速度非常慢。
scikit-image是基于scipy的一款图像处理包,它将图片作为numpy数组进行处理,正好与matlab一样,因此,我们最终选择scikit-image进行数字图像处理。
skimage包的全称是scikit-image SciKit (toolkit for SciPy) ,它对scipy.ndimage进行了扩展,提供了更多的图片处理功能。它是由python语言编写的,由scipy 社区开发和维护。
skimage包由许多的子模块组成,各个子模块提供不同的功能。
主要子模块列表如下
| 子模块名称 | 主要实现功能 |
|---|---|
| io | 读取、保存和显示图片或视频 |
| data | 提供一些测试图片和样本数据 |
| color | 颜色空间变换 |
| filters | 图像增强、边缘检测、排序滤波器、自动阈值等 |
| draw | 操作于numpy数组上的基本图形绘制,包括线条、矩形、圆和文本等 |
| transform | 几何变换或其它变换,如旋转、拉伸和拉东变换等 |
| morphology | 形态学操作,如开闭运算、骨架提取等 |
| exposure | 图片强度调整,如亮度调整、直方图均衡等 |
| feature | 特征检测与提取等 |
| measure | 图像属性的测量,如相似性或等高线等 |
| segmentation | 图像分割 |
| restoration | 图像恢复 |
| util | 通用函数 |
numpy
NumPy- 简介
NumPy 是一个 Python 包。 它代表 “Numeric Python”。 它是一个由多维数组对象和用于处理数组的例程集合组成的库。
Numeric,即 NumPy 的前身,是由 Jim Hugunin 开发的。 也开发了另一个包 Numarray ,它拥有一些额外的功能。 2005年,Travis Oliphant 通过将 Numarray 的功能集成到 Numeric 包中来创建 NumPy 包。 这个开源项目有很多贡献者。
NumPy 操作
使用NumPy,开发人员可以执行以下操作:
- 数组的算数和逻辑运算。
- 傅立叶变换和用于图形操作的例程。
- 与线性代数有关的操作。 NumPy 拥有线性代数和随机数生成的内置函数。
NumPy - Ndarray 对象
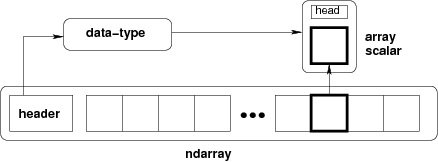
NumPy 中定义的最重要的对象是称为 ndarray 的 N 维数组类型。 它描述相同类型的元素集合。 可以使用基于零的索引访问集合中的项目。
ndarray中的每个元素在内存中使用相同大小的块。 ndarray中的每个元素是数据类型对象的对象(称为 dtype)。
从ndarray对象提取的任何元素(通过切片)由一个数组标量类型的 Python 对象表示。 下图显示了ndarray,数据类型对象(dtype)和数组标量类型之间的关系。
它从任何暴露数组接口的对象,或从返回数组的任何方法创建一个ndarray。
1 | numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0) |
上面的构造器接受以下参数:
| 序号 | 参数及描述 |
|---|---|
| 1. | object 任何暴露数组接口方法的对象都会返回一个数组或任何(嵌套)序列。 |
| 2. | dtype 数组的所需数据类型,可选。 |
| 3. | copy 可选,默认为true,对象是否被复制。 |
| 4. | order C(按行)、F(按列)或A(任意,默认)。 |
| 5. | subok 默认情况下,返回的数组被强制为基类数组。 如果为true,则返回子类。 |
| 6. | ndmin 指定返回数组的最小维数。 |
NumPy-asarray函数
此函数类似于numpy.array,除了它有较少的参数。 这个例程对于将 Python 序列转换为ndarray非常有用。
1 | numpy.asarray(a, dtype = None, order = None) |
构造器接受下列参数:
| 序号 | 参数及描述 |
|---|---|
| 1. | a 任意形式的输入参数,比如列表、列表的元组、元组、元组的元组、元组的列表 |
| 2. | dtype 通常,输入数据的类型会应用到返回的ndarray |
| 3. | order 'C'为按行的 C 风格数组,'F'为按列的 Fortran 风格数组 |
img.shape[:2] 取彩色图片的长、宽。
如果img.shape[:3] 则取彩色图片的长、宽、通道。
关于img.shape[0]、[1]、[2]
img.shape[0]:图像的垂直尺寸(高度或长度)
img.shape[1]:图像的水平尺寸(宽度)
img.shape[2]:图像的通道数
在矩阵中,[0]就表示行数,[1]则表示列数。NumPy - 数据类型
NumPy 支持比 Python 更多种类的数值类型。 下表显示了 NumPy 中定义的不同标量数据类型。
| 序号 | 数据类型及描述 |
|---|---|
| 1. | bool_ 存储为一个字节的布尔值(真或假) |
| 2. | int_ 默认整数,相当于 C 的long,通常为int32或int64 |
| 3. | intc 相当于 C 的int,通常为int32或int64 |
| 4. | intp 用于索引的整数,相当于 C 的size_t,通常为int32或int64 |
| 5. | int8 字节(-128 ~ 127) |
| 6. | int16 16 位整数(-32768 ~ 32767) |
| 7. | int32 32 位整数(-2147483648 ~ 2147483647) |
| 8. | int64 64 位整数(-9223372036854775808 ~ 9223372036854775807) |
| 9. | uint8 8 位无符号整数(0 ~ 255) |
| 10. | uint16 16 位无符号整数(0 ~ 65535) |
| 11. | uint32 32 位无符号整数(0 ~ 4294967295) |
| 12. | uint64 64 位无符号整数(0 ~ 18446744073709551615) |
| 13. | float_ float64的简写 |
| 14. | float16 半精度浮点:符号位,5 位指数,10 位尾数 |
| 15. | float32 单精度浮点:符号位,8 位指数,23 位尾数 |
| 16. | float64 双精度浮点:符号位,11 位指数,52 位尾数 |
| 17. | complex_ complex128的简写 |
| 18. | complex64 复数,由两个 32 位浮点表示(实部和虚部) |
| 19. | complex128 复数,由两个 64 位浮点表示(实部和虚部) |
NumPy 数字类型是dtype(数据类型)对象的实例,每个对象具有唯一的特征。 这些类型可以是np.bool_,np.float32等。
np.tile
1 | np.tile(data,(x,y)) |
此函数为扩展函数,data为要扩展的数据,类型为np类型数组,x,扩展行数,y扩展列数,如下代码测试
数据类型对象 (dtype)
数据类型对象描述了对应于数组的固定内存块的解释,取决于以下方面:
- 数据类型(整数、浮点或者 Python 对象)
- 数据大小
- 字节序(小端或大端)
- 在结构化类型的情况下,字段的名称,每个字段的数据类型,和每个字段占用的内存块部分。
- 如果数据类型是子序列,它的形状和数据类型。
matplotlib
Matplotlib 是 Python 的绘图库。 它可与 NumPy 一起使用,提供了一种有效的 MatLab 开源替代方案。 它也可以和图形工具包一起使用,如 PyQt 和 wxPython。在项目中用于绘图,显示图像。
pyplot简介
pyplot是一个函数集合,能够让matplotlib像matlib一样工作,每一个函数都会对一个figure做出一些改变,例如,创建一个figure,在一个figure里创建一个plotting area,在plotting area里画一些线,在plot里加一些标签等
在pyplot函数调用之间会保留着各种状态,比如当前figure和plotting area和当前的axes(这里的axes是指figure中axes部分,不是指数学上的axis的复数)
pyplot API没有面像对象API灵活,这里能看到的大部函数都是从一个Axes对象的方法,建议看文档中的例子了解它是怎么工作的
用pyplot快速创建一张图
1 | import matplotlib.pyplot as plt |

pyplot
为什么x轴是0-3,y轴是1-4,如果你给plot传入一个数组,plot会假设是一个y值的序列,然后自动创建相应的x值,因为python从0开始,默认的x向量与y同样长度,则x为[0,1,2,3]
plot是一个万能命令,它可以任意数里的参数,例如,画一个x-y二维图像,可以这样用命令
1 | plt.plot([1,2,3,4],[1,4,9,16]) |

plot
规定plot的形式
对于每个成对的x,y,还有一个可选的第三个参数,用来指定画线的颜色和类型,格式化的字母符号借鉴于matlab,你能把颜色符号与线类型连在一起,默认的格式化符号是’b-‘,就是蓝色的实线,如果你想画一个红色图点,可以
1 | plt.plot([1,2,3,4],[1,4,9,16],'ro') |

plot
plot文档里有所有的格式化参数,例子中axis()使用一个list [xmin,xmax,ymin,ymax]来指定可见范围
如果matplotlib只能用lists,那对于数字处理就没什么用了.一般来讲,你可以用numpy.array,实际上,所有序列都被内部转换成numpy.array,下面的例子用不同的形式画了一些线
1 | import numpy as np |

plot
使用关键字plotting
有一些实例,是通过字符串访问变量里的数据,例numpy.recarray,pandas.DataFrame
matplotlib可以让你提供一些带有关键字字典的对象,如果是这样的对象,plot可以把字符串和变量关联起来
1 | data = {'a': np.arange(50), |

plot
使用分类变量做图
也可以使用分类变量做图,matlibplot有很多函数可以传入分类变量
1 | names = ['group_a', 'group_b', 'group_c'] |

plot
控制线属性
线有很多属性,如线宽,样式,反锯齿,有很多方式设置线的属性
- 用关键字参数设置
1 | plt.plot(x,y,linewidth=2.0) |
- 用line2D实例的setter方法,plot会返回一列Line2D对像,例,line1,line2=plot(x1,y1,x2,y2),下面我们假设只有一条线,也就是返回的列表长度为1,我们元组拆包得到列表的第一个元素
1 | line, = plt.plot(x, y, '-') |
- 用setp命令,下面这个例子用一个matlab命令设置一条线的多个属性,setp可以传入一个或一列对象,可以使用关键字设置属性
1 | lines = plt.plot(x1, y1, x2, y2) |
| Property | Value Type |
|---|---|
| alpha | float |
| color or c | 任何matlibplot颜色 |
获取可设置属性的列表,调用setp函数
1 | In [69]: lines = plt.plot([1, 2, 3]) |
使用多个figure和axes
Matlab和pyplot,有一个当前figure和当前axes的概念,所有的plot命令都会作用在当前axes上,函数gca()返回当前axes,gcf()返回当前figure
通常,你不用担心这个,因为都在内部处理了这些问题,下面是一个创建两个subplot的脚本
1 | def f(t): |

plot
这里的的figure()是可选的,因为默认情况自动创建了figure(1),还有如果你不指定任何subplot,会默认创建subplot(111),subplot指定行数,列数,plot序号,plot序号的范围是1到行数乘以列数.如果行列数相乘小于10,参数里的逗号是可选的,因为subplot(211)默认是指subplot(2,1,1)
你可以创建任何数量的subplot和axes,如果你想用axes()命令手动指定axes位置(例如不是一个矩形),你可以用axes([left,bottom,width,height]),这里所有数都是小数(0 to1)
可以多次用一个增长的数当参数调用figure()创建多个figures,当然,每个figure都包括多个subplot和axes
1 | import matplotlib.pyplot as plt |
clf()可以清除当前figure,cla()可以清除当前axes,如果你觉得内部状态不好用,你可以用弱状态的面向对象API来代替它
如果你创建了多个figure,你需要注意一件事,figure是在调用close()的时候内存才被释放,删除所有figure,或用窗口管理器关闭窗口是不行的,因为pyplot在close()调用之前会有很多内部引用
使用text
text()命令可以在任何位置填加文本,xlabel,ylabel和title可以在指定的地方填加文本
1 | mu, sigma = 100, 15 |

plot
所有的text()命令都会返回matplotlib.text.Text实例,和线段一样,你可以在函数里或者setp里用关键字参数自定义属性
1 | t = plt.xlabel('my data', fontsize=14, color='red') |
文本里用数学表达式
matplotlib里文本里可以用Tex方程表达式,例如,你想写sigma=15,你可以用Tex表达式,然后用$括起来
1 | plt.title(r'$\sigma_i=15$') |
前面的r很重要,它意味着\是字符串,不要当成python转义符,matplotlib有一个内置的Tex解析器和布局引擎,和自己的数字字体,也就是说可以在跨平台的时候不用安装Tex,如果安装了LaTex和dvipng,也可以用来做输出
注释文本
text()可以用在axes的任何位置,一个用法就是用来注释,annotate()可以很容易的提供帮助功能,有两个坐标点要考虑,xy和xytext,都是元组形式
1 | ax = plt.subplot(111) |

对数和其他非线性的axes
matplotlib不仅提供线性坐标轴刻度,而且还提供对数和分对数刻度,这种刻度对跨度很大的数据很有用,改变刻度比例很简单:
1 | plt.xscale('log') |
y轴不同刻度的例子
1 | from matplotlib.ticker import NullFormatter # useful for `logit` scale |

pillow(PIL)
读取图片:
1 | Image.open() |
array转换成image:
1 | mage.fromarray(img) |
一、使用 Image.open() 创建图像实例
Image 是 Pillow 最常用的类,他可以通过多种方式创建图像实例。
“ from PIL import Image ”导入 Image 模块。然后通过 Image 类中的 open 函数即可载入图像文件, open 函数会自动判断图片格式,只需指定文件位置即可。成功,open 函数返回一个 Image 对象;载入文件失败,则会引起 IOError 异常 。
1. 通过文件创建 Image 对象
通过文件创建 Image 图像对象是最常用的方法
**示例:**通过文件创建 Image 图像对象

代码解读:
实例属性说明:
format 图像格式
size 图像的 (宽,高) 元组
mode 常见模式,默认 RGB 真彩图像;L 为灰阶图像;CMYK 印刷色彩;RGBA 带透明度的真彩图像;YCbCr 彩色视频格式;LAB L * a * b颜色空间;HSV 等。
show() 方法为使用系统默认图片查看器显示图像,一般用于调试;
2. 从打开文件中读取
可以从文件对象读取而不是文件名,但文件对象必须实现read( ),seek( ) 和 tell( ) 方法,并且是以二进制模式打开。
**示例:**从文件对象中读取图像

3. 从 string 二进制流中读取
要从字符串数据中读取图像,需使用 io 类:

**注意:**在读取图像 header 之前将文件倒回(使用 seek(0) )。
4. 从tar文件中读取

二、读写图像
1. 格式转换并保存图像
Image 模块中的 save 函数可以保存图片,除非你指定文件格式,否则文件的扩展名就是文件格式。

注意: 如果你的图片mode是RGBA那么会出现异常,因为 RGBA 意思是红色,绿色,蓝色,Alpha 的色彩空间,Alpha 是指透明度。而 JPG 不支持透明度 ,所以要么丢弃Alpha , 要么保存为.png文件。解决方法将图片格式转换:
1 | Image.open(image_path).convert("RGB").save(outfile) # convert 转换为 RGB 格式,丢弃Alpha |
save() 函数有两个参数,如果文件名没有指定图片格式,那么第二个参数是必须的,他指定图片的格式。
2. 创建缩略图
创建缩略图 使用 Image.thumbnail( size ), size 为缩略图宽长元组。
示例: 创建缩略图

注意: 出现异常,同上一个示例,convert(“RGB”)转换图片mode。
**注意:**除非必须,Pillow不会解码或栅格数据。当你打开文件,Pillow通过文件头确定文件格式,大小,mode等数据,余下数据直到需要时才处理。这意味着打开文件非常快速,它与文件大小和压缩格式无关。
三、剪贴,粘贴、合并图像
Image类包含允许您操作图像中的区域的方法。
如:要从图像中复制子矩形图像使用 crop() 方法。
1. 从图像复制子矩形
示例: 截取矩形图像
1 | box = (100, 100, 400, 400) |
定义box元组,表示图像基于左上角为(0,0)的坐标,box 坐标为 (左,上,右,下)。注意,坐标是基于像素。示例中为 300 * 300 像素。
2. 处理子矩形并将其粘贴回来
示例: 在原图上粘贴子矩形图像
1 | region = region.transpose(Image.ROTATE_180) # 颠倒180度 |
**注意:**将子图(region) 粘贴(paste)回原图时,粘贴位置 box 的像素与宽高必须吻合。而原图和子图的 mode 不需要匹配,Pillow会自动处理。
**示例:**滚动图像
1 | from PIL import Image |
3. 分离和合并通道
Pillow 允许处理图像的各个通道,例如RGB图像有R、G、B三个通道。 split 方法分离图像通道,如果图像为单通道则返回图像本身。merge 合并函数采用图像的 mode 和 通道元组为参数,将它们合并成新图像。
**示例:**交换RGB图像的三个波段
1 | r, g, b = im.split() |
**注意:**如果要处理单色系,可以先将图片转换为’RGB‘
四. 几何变换
PIL.Image.Image 包含调整图像大小resize()和旋转 rotate() 的方法。前者采用元组给出新的大小,后者采用逆时针方向的角度。
**示例:**调整大小并逆时针旋转 45度
1 | out = im.resize((128, 128)) |
要以90度为单位旋转图像,可以使用 rotate() 或 transpose() 方法。后者也可用于围绕其水平轴或垂直轴翻转图像。
示例:
1 | out = im.transpose(Image.FLIP_LEFT_RIGHT) # 水平左右翻转 |
rotate() 和 transpose() 方法相同,他们之间没有差别, transpose() 方法比较通用。
五. 颜色变换
**示例:**在 mode 之间转换
1 | from PIL import Image |
**注意:**它支持每种模式转换为”L” 或 “RGB”,要在其他模式之间进行转换,必须先转换模式(通常为“RGB”图像)。
六. 图像增强
1. Filters 过滤器
ImageFilter 模块有很多预定义的增强过滤器,通过 filter() 方法运用。
**示例:**使用 filter()
1 | from PIL import ImageFilter |
2. 像素点处理
point() 方法可用于转换图像的像素值(如对比度),在大多数情况下,可以将函数对象作为参数传递格此方法,它根据函数返回值对每个像素进行处理。
**示例:**每个像素点扩大1.2倍
1 | out = im.point(lambda i: i * 1.2) |
上述方法可以用简单的表达式进行图像处理,还可以通过组合point()和 paste() 对图像的局部区域进行处理 。
3. 处理单独通道
1 | # 将通道分离 |
注意创建 mask 的语句:
1 | imout = im.point(lambda i: expression and 255) xxxxxxxxxx imout = im.point(lambda i: expression and 255) imout ``=` `im.point(``lambda` `i: expression ``and` `255``) |
对于 and 逻辑判断来说,expression 为 False (0) 已经能证明整个表达式为 False (0) , 否则还有对后面的结果进行判断。所以 expression 为 False (0) 返回 False (0) ,expression 为 True (本身的结果)是返回后面的 255;
同理对于 or 的逻辑判断,当前面的表达式为 True,返回前面的值;当前面表达式为 False,返回后面表达式的值。
七、高级增强
其他图像增强功能可以使用 ImageEnhance 模块中的类。从图像创建后,可以使用 ImageEnhance 快速调整图片的对比度、亮度、饱和度和清晰度。
1 | from PIL import ImageEnhance |
ImageEnhance 方法类型:
ImageEnhance.Contrast(im) 对比度
ImageEnhance.Color(im) 色彩饱和度
ImageEnhance.Brightness(im) 亮度
ImageEnhance.Sharpness(im) 清晰度
八、 动态图像
Pillow 支持一些动态图像处理(如FLI/FLC,GIF等格式)。TIFF文件同样可以包含数帧图像。
打开动态图像时,PIL 会自动加载序列中的第一帧。你可以使用 seek 和 tell 方法在不同的帧之间移动。
示例: 读取动态图像
1 | from PIL import Image |
**注意:**有些版本的库中的驱动程序仅允许您搜索下一帧。要回放文件,您可能需要重新打开它。都遇到无法回放的库时,可以使用 for 语句循环实现。
示例:for 使用 ImageSequence Iterator 类遍历动态图像
1 | from PIL import ImageSequence |
**示例:**保存动态图像
1 | im.save(out, save_all=True, append_images=[im1, im2, ...]) |
参数说明:
out 需要保存到那个文件
save_all 为True,保存图像的所有帧。否则,仅保存多帧图像的第一帧。
append_images 需要附加为附加帧的图像列表。列表中的每个图像可以是单帧或多帧图像( 目前只有GIF,PDF,TIFF和WebP支持此功能)。
九、Postscript 打印
Pillow 允许通过 Postscript Printer 在图片上添加图像或文字。
1 | from PIL import Image |
十、配置加载器 draft
某些解码器允许在从文件中读取图像时对其进行操作。这通常可用于创建缩略图时(当速度比质量更重要)加速解码并打印到单色激光打印机(仅需灰阶图像时)。
draft() 方法操作已打开但尚未加载的图像,使其尽可能匹配给定的模式和大小。它通过重新配置图像解码器来完成。仅适用于JPEG和MPO文件。
**示例:**使用 draft() 快速解码图像
1 | from PIL import Image |
输出:
1 | original = RGB (1920, 1200) |
注意: 生成的图像与请求的模式和大小可能不完全匹配。要确保图像不大于给定大小,需改用缩略图方法。
argparse
argparse是python内置的一个用于命令项选项与参数解析的模块。
主要有三个步骤:
1- 创建 ArgumentParser() 对象;
2- 调用 add_argyment() 方法添加参数;
3- 使用 parse_args() 解析添加的参数。
add_argument()
1 | ArgumentParser.add_argument(name or flags...[, action][, nargs][, const][, default] |
- name or flags:选项字符串的名字或者列表,例如foo 或者 -f, -foo;
- action:命令行遇到参数时的动作,默认值是store。store_const表示赋值为const;append表示将遇到的值存储成列表,也就是如果参数重复则会保存多个值;append_const表示将参数规范中定义的一个值保存到一个列表;count表示存储遇到的次数;此外也可以继承argparse.Action自定义参数解析;
- nargs:应该读取的命令行参数个数,可以是具体的数字,或者是?号,当不指定值时对于Positional argument使用default,对于Optional argument使用const;或者是*号,表示0或多个参数;或者是+号,表示1或多个参数;
- const:一个在action和nargs选项所需的常量值;
- default:不指定参数时的默认值;
- type:命令行参数应该被转换成的类型;
- choices:参数可允许的值的一个容器;
- required:可选参数是否可以省略(仅针对可选参数);
- help:参数的帮助信息,当指定为argparse.SUPPRESS时表示不显示该参数的帮助信息;
- metavar:在usage说明中的参数名称,对于必选参数默认就是参数名称(即上面的name or flags),对于可选参数默认是全大写的参数名称;
- dest:parse_args()方法返回的对象所添加的属性的名称。默认情况下,对于可选参数选取最长的名称,中划线转换为下划线。
图像着色系统的理论支持——计算机图形学、图像处理技术与人工智能的结合
图像归一化处理
1.什么是归一化?
归一化,Normalization,是指将在一定范围内的数值集合转换为0~1范围内。归一化的目的是控制输入向量的数值范围,不能过大或者过小。因为复杂程序运行本身已经非常耗时,如果数值过大,运行速度会更慢。
2.归一化的方法
归一化经常经常采用的是
最大最小值归一化

x’为归一化之后的数值,x为需要归一化处理的数值

Z-score归一化
Z-score给予原始数据的均值(mean)和标准差(standard deviation)进行数据的归一化,公式如下,意义为数值距离均值有几个标准差,当E(Z)=0,SD(Z)=1,即均值为0,标准差为1,则表示经过处理后的数据符合标准正态分布。

该方法适用大多数类型的数据,但是它是一种中心化方法,会改变原有数据的分布结构,同样也不适用于稀疏数据的处理。

3.图像归一化处理
输入图像每个像素值范围是0到255之间的数值,对于计算机来说这个数值太大了,所以像素值归一化处理一般是将像素值除以255,得到0到1之间的数值来进行计算。在项目中,为了防止图像处理后数值过大,导致程序运行出错,或栈空间不足,所以我们这里也对图像就行了一个规范化处理。
卷积

**积操作其实就是每次取一个特定大小的矩阵(蓝色矩阵中的阴影部分),然后将其对输入
(图中蓝色矩阵)依次扫描并进行内积的运算过程。**可以看到,阴影部分每移动一个位置就会计算得到一个卷积值(绿色矩阵中的阴影部分),当
扫描完成后就得到了整个卷积后的结果
(绿色矩阵)。
同时,我们将这个特定大小的矩阵称为卷积核,即convolutional kernel或kernel或filter或detector,它可以是一个也可以是多个;将卷积后的结果
称为特征图,即feature map,并且每一个卷积核卷积后都会得到一个对应的特征图;最后,对于输入
的形状,都会用三个维度来进行表示,即宽(width),高(high)和通道(channel)。例如图1中输入
的形状为
[7,7,1]。
多卷积核
注意,在上面笔者提到了卷积核的个数还可以是多个,那我们为什么需要多个卷积核进行卷积呢?在上一篇文章中我们介绍到:对于一个卷积核,可以认为其具有识别某一类元素(特征)的能力;而对于一些复杂的数据来说,仅仅只是通过一类特征来进行辨识往往是不够的。因此,通常来说我们都会通过多个不同的卷积核来对输入进行特征提取得到多个特征图,然再输入到后续的网络中。

图 2. 多卷积核卷积图
如图2所示,对于同一个输入,通过两个不同的卷积核对其进行卷积特征提取,最后便能得到两个不同的特征图。从图2右边的特征图可以发现,上面的特征图在锐利度方面明显会强于下面的特征图。当然,这也是使用多卷积核进行卷积的意义,探测到多种特征属性以有利于后续的下游任务。
卷积的计算
到此为止, 对于卷积的原理和意义就算是交待完了,并且通过这些动态图片的展示,我们也有了更为直观的了解。但所谓数无形时少直觉,形少数时难入微。因此,下面我们就以单通道(灰度图)和三通道的输入来实际计算一下整个卷积的过程。
单通道单卷积核
如图3所示,现在有一张形状为[5,5,1]的灰度图,我们需要用图3右边的卷积核对其进行卷积处理,同时再考虑到偏置的作用。那么其计算过程是怎么样的呢?
 图 3. 输入与卷积
图 3. 输入与卷积
如图4所示,右边为卷积后的特征图(feature map),左边为卷积核对输入图片左上放进行卷积时的示意图。因此,对于这个部分的计算过程有:
 图 4. 单通道单卷积(一)
图 4. 单通道单卷积(一)
同理,对于最右下角部分卷积计算过程有:
 图 5. 单通道单卷积(二)
图 5. 单通道单卷积(二)
因此,对于最后卷积的结果,我们得到的将是一个如图5右边所示形状为[3,3,1]的特征图。到此我们就把单通道单卷积的计算过程介绍完了。下面我们再来看单通道多卷积核的例子。
单通道多卷积核
如图6所示,左边依旧为输入矩阵,我们现在要用右边所示的两个卷积核对其进行卷积处理。

图 6. 单通道多卷积(一)
同时可以看到,图6中右边的第一个卷积核就是图3里的卷积核,其结果也就是图5中计算得到的结果。对于旁边的卷积核,其计算过程如图7所示:
 图 7. 单通道多卷积(二)
图 7. 单通道多卷积(二)
最后我们便能得到如图8右边所示的,形状为[3,3,2]的卷积特征图,其中2表示两个特征通道。
 图 8. 单通道多卷积结果
图 8. 单通道多卷积结果
到此,对于单通道的卷积计算过程就介绍完了。但通常情况下,我们遇到得更多的就是对多通道的输入进行卷积处理,例如包含有RGB三个通道的彩色图片等。接下来,笔者就开始介绍多通道的卷积计算过程。
多通道单卷积核
对于多通道的卷积过程,总体上还是还是同之前的一样,都是每次选取特定位置上的神经元进行卷积,然后依次移动直到卷积结束。下面我们先来看看多通道单卷积核的计算过程。
 图 9. 多通道单卷积输入
图 9. 多通道单卷积输入
如图9所示,左边为包含有三个通道的输入,右边为一个卷积核和一个偏置。注意,强调一下右边的仅仅只是一个卷积核,不是三个。笔者看到不少人在这个地方都会搞错。因为输入是三个通道,所以在进行卷积的时候,对应的每一个卷积核都必须要有三个通道才能进行卷积。下面我们就来看看具体的计算过程。
 图 10. 多通道单卷积核图
图 10. 多通道单卷积核图
如图10所示,右边为卷积后的特征图(feature map),左边为一个三通道的卷积核对输入图片左上放进行卷积时的示意图。因此,对于这个部分的计算过程有:
![[公式]](E:\MyBlog\public\img\逆卷积公式.svg)
同理,对于其它部分的卷积计算过程也类似于上述计算步骤。由此我们便能得到如图10右边所示卷积后的形状为[3,3,1]的特征图。
多通道多卷积核
在介绍完多通道单卷积核的计算过程后,我们再来看看多通道多卷积核的计算过程。
 图 11. 多通道多卷积核图
图 11. 多通道多卷积核图
如图11所示,左边依旧为输入矩阵,我们现在要用右边所示的两个卷积核对其进行卷积处理。同时可以看到,第一个卷积核就是图9中所示的卷积核,其结果如图10所示。对于第二个卷积核,其计算过程也和式子类似,都是将每个通道上的卷积结果进行相加,最后再加上偏置。因此,最后我们便能得到如图12右边所示的,形状为
[3,3,2]的卷积特征图,其中2表示两个特征通道。
 图 12. 多通道多卷积核结果图
图 12. 多通道多卷积核结果图
同时,从上面单通道卷积核多通道卷积的计算过程可以发现:
(1)原始输入有多少个通道,其对应的一个卷积核就必须要有多少个通道,这样才能与输入进行匹配,也才能完成卷积操作。换句话说,如果输入数据的形状为[n,n,c],那么对应每个卷积核的通道数也必须为c。
(2)用k个卷积核对输入进行卷积处理,那么最后得到的特征图一定就会包含有k个通道。例如,输入为[n,n,c],且用k个卷积核对其进行卷积,则卷积核的形状必定为[w1,w2,c,k],最终得到的特征图形状必定为[h1,h2,k];其中w1,w2为卷积核的宽度,h1,h2为卷积后特征图的宽度。
为什么需要深度卷积
所谓深度卷积就是卷积之后再卷积,然后再卷积。卷积的次数可以是几次,也可以是几十次、甚至可以是几百次。因此,在全连接网络中我们可以通过更深的隐藏层来获取到更高级和更抽象的特征,以此来提高下游任务的精度。因此,采用深度卷积也是处于同样的目的。
逆卷积
核心原理
最基本的形式

如果加入了stride呢?

如果加入了padding呢?


如果是最一般的形式,即既有padding,又有stride呢?
空洞卷积(Dilated Convolution)
简介
空洞卷积也叫扩张卷积或者膨胀卷积,简单来说就是在卷积核元素之间加入一些空格(零)来扩大卷积核的过程。
空洞卷积的简单原理。下图是常规卷积和空洞卷积的动图对比:
常规卷积:

空洞卷积:

假设以一个变量a来衡量空洞卷积的扩张系数,则加入空洞之后的实际卷积核尺寸与原始卷积核尺寸之间的关系:K = K + (k-1)(a-1)
其中k为原始卷积核大小,a为卷积扩张率(dilation rate),K为经过扩展后实际卷积核大小。除此之外,空洞卷积的卷积方式跟常规卷积一样。我们用一个扩展率a来表示卷积核扩张的程度。比如说a=1,2,4的时候卷积核核感受野如下图所示:

在这张图像中,3×3 的红点表示经过卷积后,输出图像是 3×3 像素。尽管所有这三个扩张卷积的输出都是同一尺寸,但模型观察到的感受野有很大的不同。当a=1,原始卷积核size为3 * 3,就是常规卷积。a=2时,加入空洞之后的卷积核:size=3+(3-1) * (2-1)=5,对应的感受野可计算为:(2 ^(a+2))-1=7。a=3时,卷积核size可以变化到3+(3-1)(4-1)=9,感受野则增长到 (2 ^(a+2))-1=15。有趣的是,与这些操作相关的参数的数量是相等的。我们「观察」更大的感受野不会有额外的成本。因此,扩张卷积可用于廉价地增大输出单元的感受野,而不会增大其核大小,这在多个扩张卷积彼此堆叠时尤其有效。
论文《Multi-scale context aggregation by dilated convolutions》的作者用多个扩张卷积层构建了一个网络,其中扩张率 a 每层都按指数增大。由此,有效的感受野大小随层而指数增长,而参数的数量仅线性增长。这篇论文中扩张卷积的作用是系统性地聚合多个比例的形境信息,而不丢失分辨率。这篇论文表明其提出的模块能够提升那时候(2016 年)的当前最佳形义分割系统的准确度。请参阅论文了解更多信息。
为什么要增大感受野?
这里涉及到语义分割的一些发展历程,之前FCN率先提出以全卷积方式来处理像素级别的分割任务时,包括后来奠定语义分割baseline地位的U-Net,网络结构中存在大量的池化层来进行下采样,大量使用池化层的结果就是损失掉了一些信息,在解码上采样重建分辨率的时候肯定会有影响。特别是对于多目标、小物体的语义分割问题,以U-Net为代表的分割模型一直存在着精度瓶颈的问题。而基于增大感受野的动机背景下就提出了以空洞卷积为重大创新的deeplab系列分割网络。如下图所示:

如何计算CNN的感受野
感受野(Receptive Field)是CNN中最重要的基础概念之一。深入理解感受野对于一些任务的网络结构设计和优化有着重要意义,比如语义分割模型的空洞卷积,其中就涉及到对感受野的深刻理解。
所谓感受野,是指输出特征图上某个像素对应到输入空间中的区域范围。所以感受野可以理解为特征图像素到输入区域的映射。 先来回顾一个从输入到特征图的计算过程:

其中n_in为输入size,p为padding大小,f为卷积核size,s为卷积步长。假设输入大小为5 * 5,f=3 * 3,padding为1 * 1,卷积步长为2 * 2,那么输出特征图size根据公式可计算为3 * 3。如下图所示:

然后我们继续对3 * 3的特征图执行卷积,卷积参数同第一次卷积一样,可得输出特征图size为2 * 2。我们把输入、两次卷积过程和对应特征图放到一起看一下:

可以看到两次卷积的特征图分别对应到输入空间的感受野大小,第一次卷积对应关系如图中绿色线条所示,感受野大小为3 * 3,第二次卷积对应关系如图中黄色线条所示,感受野大小为7 * 7。所以关键问题是特征图和输入空间的对应关系中,感受野的大小是如何计算的?
下面我们给出感受野大小的计算公式:

其中RF_l+1为当前特征图对应的感受野大小,也就是我们要计算的目标感受野,RF_l为上一层特征图对应的感受野大小,f_l+1为当前卷积层卷积核大小,最后一项连乘项则表示之前卷积层的步长乘积。
根据感受野的计算公式我们来看上图中两次卷积的感受野计算过程:
原始输入size为5 * 5,第一层卷积核为3 * 3,输入步长为1,输入层初始化感受野为1 * 1,根据公式计算可得第一层卷积后的特征图对应的输入空间的感受野大小为1+(3-1) * 1=3。
第一层卷积输出特征图的感受野size为3,第二层卷积核size为3,卷积步长为2,则第二层的的感受野size计算为3+(3-1) * 2 * 1=7。所以我们可以看到当前层特征图的感受野大小对应到输入空间与前层的感受野和卷积步长以及当前层的卷积核大小密切相关。当步长大于1时,感受野的大小会呈现指数级增长。

注意: 感受野还有一点比较重要的是,对于一个卷积特征图而言,感受野中每个像素并不是同等重要的,越接近感受野中间的像素相对而言就越重要。
空洞卷积主要有三个作用:
扩大感受野。但需要明确一点,池化也可以扩大感受野,但空间分辨率降低了,相比之下,空洞卷积可以在扩大感受野的同时不丢失分辨率,且保持像素的相对空间位置不变。简单而言,空洞卷积可以同时控制感受野和分辨率。
获取多尺度上下文信息。当多个带有不同dilation rate的空洞卷积核叠加时,不同的感受野会带来多尺度信息,这对于分割任务是非常重要的。
可以降低计算量,不需要引入额外的参数,如上图空洞卷积示意图所示,实际卷积时只有带有红点的元素真正进行计算。
RGB与LAB颜色空间的转换
RGB
RGB颜色空间是一种大的分类,具体而言RGB空间还包含多种空间,其中sRGB是HP和Microsoft联合制定的标准RGB空间,除此之外还有Adobe RGB,Apple RGB,ColorMatch RGB等等,他们通过不同的方式表示RGB三种颜色,使得它们具有不同的色彩宽度。
计算机色彩显示器显示色彩的原理与彩色电视机一样,都是采用R、G、B相加混色的原理,通过发射出三种不同强度的电子束,使屏幕内侧覆盖的红、绿、蓝磷光材料发光而产生色彩的。这种色彩的表示方法称为RGB色彩空间表示。在多媒体计算机技术中,用的最多的是RGB色彩空间表示。
根据三基色原理,用基色光单位来表示光的量,则在RGB色彩空间,任意色光F都可以用 RGB三色不同分量的相加混合而成:
我们可知自然界中任何一种色光都可由R、G、B三基色按不同的比例相加混合而成,当三基色分量都为0(最弱)时混合为黑色光;当三基色分量都为k(最强)时混合为白色光。任意色彩F是这个立方体坐标中的一点,调整三色系数r、g、b中的任一系数都会改变F的坐标值,也即改变了F的色值。RGB色彩空间采用物理三基色表示,因而物理意义很清楚,适合彩色显象管工作。然而这一体制并不适应人的视觉特点。因而,产生了其它不同的色彩空间表示法。

LAB
RGB模式是一种发光屏幕的加色模式,CMYK模式是一种颜色反光的印刷减色模式。而Lab模式既不依赖光线,也不依赖于颜料,它是CIE组织确定的一个理论上包括了人眼可以看见的所有色彩的色彩模式。Lab模式弥补了RGB和CMYK两种色彩模式的不足。
Lab模式由三个通道组成,但不是R、G、B通道。它的一个通道是亮度,即L,取值范围是[0,100],表示从纯黑到纯白。另外两个是色彩通道,用A和B来表示。A通道包括的颜色是从深绿色(底亮度值)到灰色(中亮度值)再到亮粉红色(高亮度值),取值范围是[127,-128];B通道则是从亮蓝色(底亮度值)到灰色(中亮度值)再到黄色(高亮度值),取值范围是[127,-128]。因此,这种色彩混合后将产生明亮的色彩。
Lab模式所定义的色彩最多,且与光线及设备无关
用处

在 Adobe Photoshop图像处理软件中,TIFF格式文件中,PDF文档中,都可以见到Lab颜色空间的身影。而在计算机视觉中,尤其是颜色识别相关的算法设计中,rgb,hsv,lab颜色空间混用更是常用的方法。
pre-trained模型的使用
预训练的模型通过将其权重和偏差矩阵传递给新模型来共享他们的学习成果。
- 当数据集小的时候:
A、相似度高:如果训练数据和pretrained model所用的数据相似度较高的时候,我们不需要从头造轮子,只需要修改最后的输出的softmax即可,采用已经训练好的结构来提取特征。
B、相似度低:如果训练数据和pretrained model所用的数据相似度较低,假设网络一共有n层,我们可以冻结预训练模型中的前k个层中的权重,然后重新训练后面的n-k个层,并修改最后一层的分类器的输出类即可。因为数据的相似度不高,重新训练的过程就变得非常关键。而新数据集大小的不足,则是通过冻结预训练模型的前k层进行弥补。(相似度不高的时候重新训练是很有必要的,而冻结前K层的原因是为了弥补训练数据量不充足,当然了数据量不足可以采取数据增强方法,比如:对称,旋转,随机切,扭曲等等)
2.当数据集大的时候:
A、相似度高:这个是非常好也非常难得的情况,此时只要采用pretrained模型不需要改变任何参数即可,即保持模型原有的结构和初始权重不变,随后在新数据集的基础上重新训练。
B、相似度低:因为我们有一个很大的数据集,所以神经网络的训练过程将会比较有效率。然而,因为实际数据与预训练模型的训练数据之间存在很大差异,采用预训练模型将不会是一种高效的方式。因此最好的方法还是将预处理模型中的权重全都初始化后在新数据集的基础上重头开始训练。
网络训练的流程
网络的训练过程如下:
选定训练组,从样本集中分别随机地寻求N个样本作为训练组;
将各权值、阈值,置成小的接近于0的随机值,并初始化精度控制参数和学习率;
从训练组中取一个输入模式加到网络,并给出它的目标输出向量;
计算出中间层输出向量,计算出网络的实际输出向量;
将输出向量中的元素与目标向量中的元素进行比较,计算出输出误差;对于中间层的隐单元也需要计算出误差;
依次计算出各权值的调整量和阈值的调整量;
调整权值和调整阈值;
当经历M后,判断指标是否满足精度要求,如果不满足,则返回(3),继续迭代;如果满足就进入下一步;
训练结束,将权值和阈值保存在文件中。这时可以认为各个权值已经达到稳定,分类器已经形成。再一次进行训练,直接从文件导出权值和阈值进行训练,不需要进行初始化。
可参考:卷积神经网络超详细介绍
池化
1、二维最大池化
返回滑动窗口中的最大值

2、填充、步幅、和多个通道
池化层与卷积层类似,都具有填充和步幅;
没有可学习的参数;
在每个输入通道应用池化层以获得相应的输出通道;
输出通道数=输入通道数;
3、平均池化层
最大池化层:每个窗口中最强的模式信号
平均池化层:将最大池化层中的最大操作替换为平均;
4、总结
池化层返回窗口中最大或平均值;
缓解卷积层对位置的敏感性;
同样有窗口大小、填充和步幅作为超参数。
自监督介绍
一句话总结,传统的深度学习需要大量的人工标注数据,自监督学习通过pretext task(前置任务)学习数据内部分布,生成伪标签来训练模型,打破了标签数据的局限,更接近人工智能的本质。预测图像的颜色,本质是学习图像的语义特征。
为什么这么说,就是站在人类认知的角度,我们为什么看到一张参天大树的图像,可以判断它是直立的?因为我们知道天空和地面的上下位置关系,树的常见状态我们也知道,所以我们能不假思索地判断出来。预测图片拼图和上色也是一样,我们学习到了图像的语义特征信息。而自监督学习可以不需要人为的标签标注,也是充分学习了图像的内部数据的结果。
项目结构
总体思路
对一个Gray的图片建立到RGB的映射模型是一个比较复杂的回归问题,且效果难以把控。所以这里提出使用Lab颜色空间作为整个模型的映射机制,由于Lab将色彩信息放置在ab两个通道的特性,而L通道仅保存亮度等信息,这些信息可以从Gray图直接得到。
这就是说模型的输入是Lab中L通道的矩阵,目标是一个ab两通道的二层矩阵,建立的是从L向ab的映射关系。
当得到ab通道的信息再组合上L通道信息即得到彩色的Lab图片,而Lab图片到RGB图片的转换是固定的,也就是说,得到了期待的彩色RGB图片。
前期优化
那么,对训练过程中的一张图片,得到它的L信息很容易,得到ab信息也很容易,但是Lab色彩空间有个很大的问题就是其中包含了很多人类不可见的色彩,这些色彩是干扰模型预测的要素。在此,提出来一种新的思路,选取数据集中常见的色彩,组成ab值对,作为ab通道的信息。
实验证明,这种思路很成功,最后一共得到了313个常用值对信息。这就是说,预测的目标变为了一个值对或者313个值对的概率分布,原来复杂的回归变成了一个简单不少的分类问题。
当然,这里有一个问题,那就是训练时对于每个RGB图片(转为Lab图片),如何得到其目标的ab值对?这里使用了5近邻搜索法得到像素点的ab值对。
后续处理
得到了313个ab值对的颜色概率,如何将其映射回ab通道的色彩呢,在尝试了平均法和分立法之后(前者上色过于融合后者过于分界),使用兼有两种要求的模拟退火搜索法得到ab两个通道的矩阵。
损失函数
事实上,优化函数的研究这些年已经有了很大的发展,Adam已经可以满足本项目的需求了,但是在尝试使用分类经典的交叉熵函数时发现训练的模型上色均比较暗淡,这是因为imagenet数据集的图片普遍比较背景暗淡,为了产生比较鲜艳的色彩,提出了加上颜色再平衡系数的交叉熵函数,训练的模型效果得以改善。
模型构建
本项目模型构建基于Keras Function API(TensorFlow后端),训练与Tesla T4 16G GPU。模型提供于Github,可以使用Netron可视化h5模型。修改的交叉熵函数可见于脚本目录下的loss_function.py文件。
创新点
由于图像的颜色具有多模态性质,即一张图像的颜色可以有多种可能,因此文章不是重建图像颜色,而是预测图像颜色。
(用灰度图中物体的纹理、语义等信息作为线索,来预测可能的上色,最后的上色结果只要真实即可。这不仅降低了上色的难度,而且也符合人们的认知)颜色预测是一个多模的问题,一个物体本来就可以上不同的颜色。对这种多模性建模,为各个像素预测一个颜色的分布,这可以鼓励探索颜色的多样性,而不仅仅局限在某一种颜色中。人的目标只是优化预测结果和真实图片(ground truth)间的欧氏距离(即MSE)(L2范式),这种损失函数会把所有的颜色求平均(因为颜色具有多模态),从而导致颜色饱和度不高,色彩不丰富。
我们的基本思路,就是通过前向encoder+ 反向decoder+ab概率分布预测的网络结构
代码的模型我们主要模仿的是以下思路编写的:

也就是读取图像后,经过一系列卷积,细化图像的精读,增加鲁棒性,接着再通过逆卷积,将图像进行还原,归一化,及统一规格后,将原本rgb颜色空间变为lab空间后,我们通过训练,得到一个深度预测ab通道普遍试用而稳定的权重等参数,构成模型,利用模型为图像着色。
代码解说
1 | #__init__.py: |
1 | #base_color.py: |
1 | #神经网络模型1 |
1 | #siggraphmodel.py: |
1 | #util.py: |
1 | #demo_release.py: |
图例:

导入已训练的模型
开始着色! 在Python中加载模型
1 | python demo_release.py -i imgs/ansel_adams3.jpg |
以下加载预训练的着色器。有关如何运行模型的一些详细信息,请参见演示 demo_release.py,有一些预处理和后处理步骤:转换到实验室空间,调整大小到256x256,着色,并连接到原始的完全分辨率,并转换为RGB。
1 | #处理图像的类PIL,数据处理的numpy,PIL和Pillow只提供最基础的数字图像处理,功能有限。 |
1 | import argparse |





